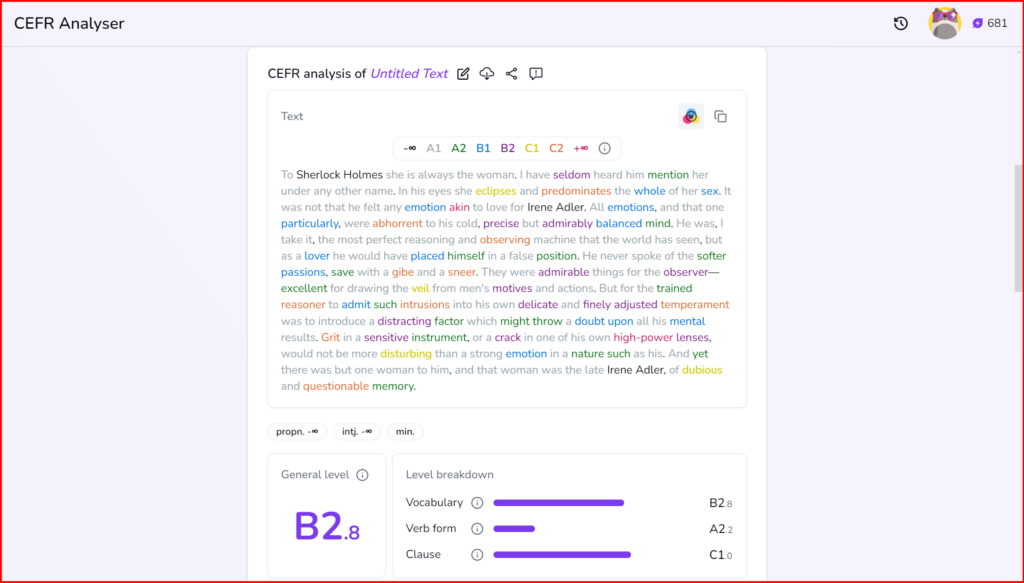
Cathoven’s Detailed Language Levels for CEFR
The CEFR is a universal framework used to describe language proficiency levels, widely employed in curriculum design and language assessment. Cathoven uses AI technology to swiftly and accurately analyze the CEFR levels of texts. Additionally, it breaks down language difficulty into more detailed levels beyond the original six CEFR categories. This article will explain how CEFR describes different language proficiency levels, why Cathoven further divides these levels into several sub-levels, and the principles behind its grading system.
What is CEFR?
CEFR stands for the Common European Framework of Reference for Languages. It is an internationally recognized framework used to assess language proficiency levels across different languages. CEFR divides language proficiency into six main levels: A1, A2, B1, B2, C1, and C2, which can be grouped into three broad categories: Basic User (A1-A2), Independent User (B1-B2), and Proficient User (C1-C2). Each level corresponds to a set of descriptors (“Can-do” statements) that outline what learners can achieve in different language contexts. This framework provides a standardized way to describe and evaluate language skills, facilitating communication and alignment in language education and assessment worldwide.
Limitations of CEFR Descriptors
While the CEFR is widely used for assessing language proficiency, the six-level CEFR descriptors have limitations, especially when applied to the language learning process. Here are two major criticisms:
1. Broadness of CEFR Descriptors: CEFR descriptors grade mastery of each skill on a six-level scale (from A1 to C2). However, this specification may be too broad, especially for textbook authors and teachers who need to accurately assess students’ subtle language progress.
2. Lack of Detailed Definition of Syntactic Complexity (SC): Research points out that CEFR descriptors lack detailed definitions of syntactic complexity, making it difficult to use the scale to grade the syntactic complexity of beginners’ writing (Khushik & Huhta, 2020).
Developments to Address CEFR Limitations
To address these limitations and provide more detailed descriptions for different CEFR levels, Reference Level Descriptions (RLDs) were created to describe proficiency levels for national and regional languages. These descriptions are developed based on CEFR for individual languages by national teams using various approaches. One well-known project is the English Profile Programme (englishprofile.org), which specifies English language levels and provides detailed language examples for each level. Additionally, some researchers and educators have updated CEFR descriptors and divided the scale into several sub-levels. For example, the Lingualevel project in Switzerland developed self-assessment descriptors for learners in lower secondary education (2009), further dividing the levels into sub-levels: A1.1, A1.2, A2.1, A2.2, B1.1, B1.2.
How Cathoven Develops Its CEFR Descriptors
Cathoven recognizes the broadness of the CEFR scale and aims to provide a more detailed and accurate difficulty level. To achieve this, Cathoven splits each CEFR level into 10 additional levels. The difficulty levels of texts are determined by the website’s AI, trained using machine learning technology. During the development of Cathoven’s CEFR analyzer tool, large volumes of texts marked by CEFR difficulty levels were input into the machine, enabling it to automatically differentiate subtle difficulty differences in texts.
This machine learning process might seem complex, but it can be understood with the following analogy. Imagine you’re learning to sort fruits by their sweetness on a scale from 1 to 6, where 1 is not sweet at all and 6 is extremely sweet. Initially, you only see examples of fruits that have been precisely categorized into these six levels. For instance, lemons are at level 1 because they’re sour, while ripe mangoes are at level 6 due to their high sugar content. As you continue learning, you notice that not all fruits fit perfectly into these categories. A slightly underripe mango might not be as sweet as a fully ripe one but sweeter than an apple. Instead of forcing it into one of the six predefined categories, you begin to see sweetness as a spectrum.
Translating this to the machine learning model: the machine starts by understanding the categorical labels (1 to 6) as discrete examples. As it receives more data, it notices the subtle variations within each category and learns the continuous nature of the feature it’s predicting—in this case, sweetness. When making predictions, the machine no longer just chooses one of the six labels. Instead, it places the new example somewhere on the continuous spectrum it has learned, such as a prediction like 4.5 for sweetness.
When Cathoven trained its AI tool, the machine learned from English texts labeled by six CEFR descriptors. With vast data to learn from, it can label a text as A2.6 instead of just A2, allowing for a more nuanced analysis of language complexity in a text.
Reference
Council of Europe. (2001). Common European framework of reference for languages: Learning, teaching, assessment. Cambridge University Press.
Khushik, G. A., & Huhta, A. (2020). Investigating syntactic complexity in EFL learners’ writing across common European framework of reference levels A1, A2, and B1. Applied Linguistics, 41(4), 506-532.